近日,山东大学数智边疆实验室与地方企业联合,在去年发布的“边疆大模型”基础上,成功研发智能助手系统,该系统深度融合命名实体识别(NER)、多语言文本标点、语境化语义解析等核心技术,实现边疆研究领域从数据治理到知识挖掘的全链路智能化支持。
一、技术突破:边疆大模型的跨学科融合创新
针对边疆研究长期面临的多语言混杂、历史文献标注复杂、实体关系多元等痛点,实验室基于百万级边疆专题语料库,构建了面向垂直场景的“边疆大模型”。该模型通过引入多任务联合训练框架,在通用大模型能力基础上,强化对边疆地名、民族称谓、历史事件、政策术语等特定实体识别精度,同时攻克低资源语料的自动标点与分词难题,支持现代汉语与古文的混合文本处理,为边疆文献数字化提供底层技术支撑。
二、全栈赋能:从数据治理到决策支持的一体化平台
依托该智能助手,实验室对原有“数字边疆平台”进行全面升级,形成三大核心功能模块:
1.智能文献抽取与预处理系统:实现跨境多语种专题文献一键抽取,并生成半结构化文本数据。在此基础上,实现边疆史料(如地方志、档案、碑刻)的智能标点、实体抽取与时空标签生成,处理效率较人工提升30倍。
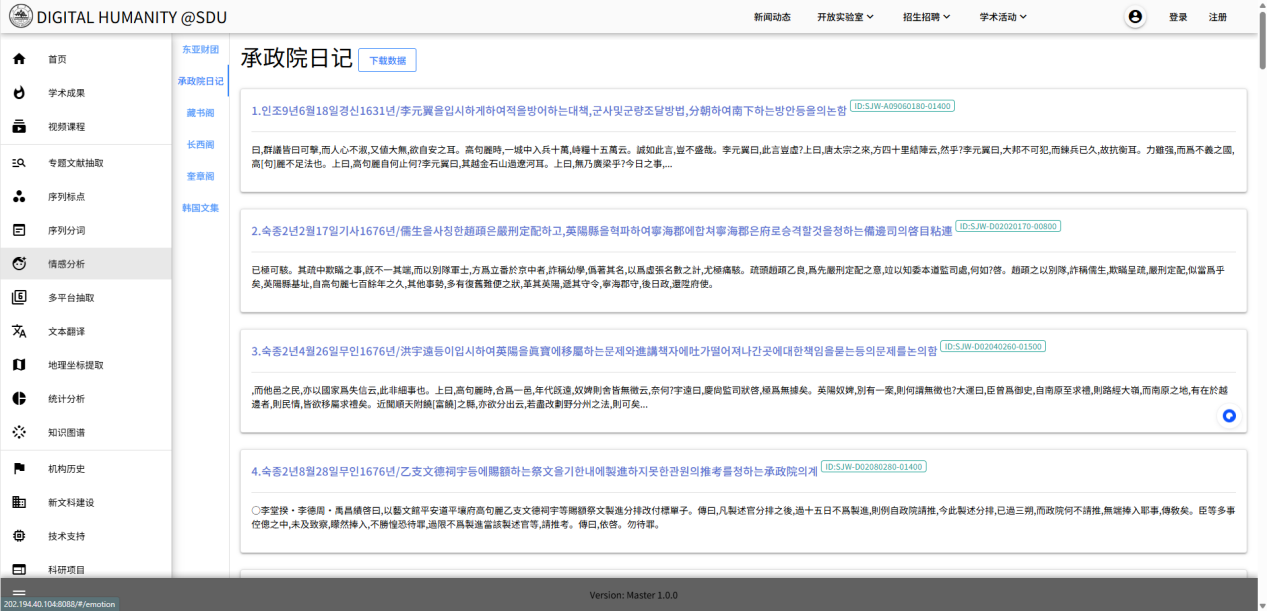
2.数典述疆智能助手一键命名实体识别:该功能运用了基于边疆综合智能体所构建的、具备 20 万节点级的边疆知识图谱。此知识图谱为多维关联网络,通过知识图谱增强(KG-RAG)技术,为一键命名实体识别功能提供有力支撑,使其能够更高效、精准地发挥相应作用。

实验室主任苗威教授表示,边疆大模型不仅是技术工具,更是连接历史与现实、学术与社会的桥梁。传统边疆研究依赖学者手工整理碎片化信息,而我们的系统能将文献“翻译”成可计算的数据,让研究者聚焦于更高维的知识发现,未来我们将开放API接口,与学界共建边疆数智生态。
目前,该成果由国家社科基金冷门绝学团队项目支持,并与智谱AI、和鲸科技等省内外企业达成战略合作。实验室计划于2025年第三季度发布开源社区版,为边疆研究范式的数字化转型。
【项目咨询】
山东大学数智边疆实验室
联系人:徐老师
联系方式:扫码添加微信或邮箱

邮箱:jianhongchen@sdu.edu.cn
—— 数智之光,照亮边疆 ——
欢迎交流、合作